|
I am a first-year Ph.D. student in Computer Science at Princeton University, advised by Prof. Zhuang Liu. I received my BS in Computer Science from Georgia Tech in 2022. At Georgia Tech, I was fortunate to be advised by Matthew Gombolay and worked as a TA for Constantinos Dovrolis. From 2022-2025, I worked at Two Sigma in the Metadata Team, where I frequently collaborated with Larry Rudolph in the Labs Team. |

|
 
|
Sachin Konan*, Larry Rudolph, Scott Affens North American Chapter of the Association for Computational Linguistics (NAACL), 2024 Official: Paper / Video / Poster / Code TLDR; The proliferation of vast data providers and inherent dirtiness of data have increased the value proposition of Semantic Types. We introduce the concept of Functional Semantic Types (FST)s which are Python classes that encapsulate the informational and functional context of columnar data. FSTs will normalize and validate data in a structured/readable manner, allowing automated cross-table joins or fast lookups. In order to scale the generation of FSTs, we leverage Foundational Models to transform serialized data-tables to FSTs. Across Kaggle, Harvard, and FactSet Data-Verses we show our method FSTO-Gen, can generate functionally and informationally correct FSTs. |

|
Sachin Konan*, Esmaeil Seraj, Matthew Gombolay Conference on Robot Learning, 2023 Official: PMLR / Video / Poster / Code TLDR; Decision Transformer (DT) is a return-conditioned system that generates the action that will achieve a desired return in a given state. Achieving high return should theoretically require drastically different behavior than low return. In the same way that search is optimized through indexing, ConDT organizes state-action embeddings by return, allowing the transformer to more easily "recall" the necessary action for that return. ConDT improves performance in Gym, Atari, and hand-grip tasks. |
|
Sachin Konan*, Esmaeil Seraj*, Matthew Gombolay International Conference on Learning Representations, 2022 Official: arXiv / Blog / Poster / Presentation / Video / Code TLDR; Collaborative teaming in multi-agent RL is challenging because agents need to consider the conditionality of their actions, which exponentially grows in complexity with the size of the action space and the number of agents. Humans excel at learning this conditionality by recursively reasoning about the actions of others, like in chess where a player A recursively considers how their player B considers how player A, and so on. We formulated a multi-agent policy gradient (InfoPG) that fosters this type of reasoning by maximizing inter-agent mutual information. InfoPG improves team-performance in Gym and Starcraft cooperative games and is robust to adversarial team-mates (Byzantine Generals Problem). |
|
|
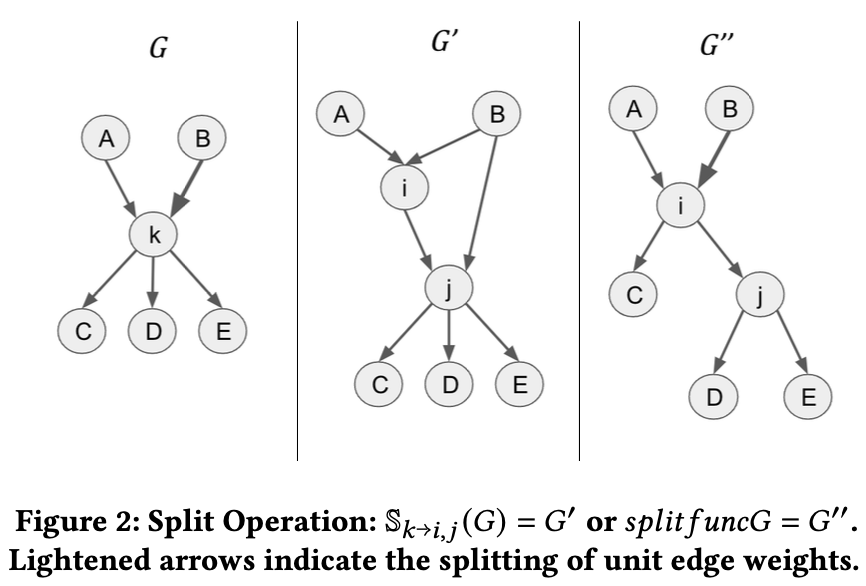
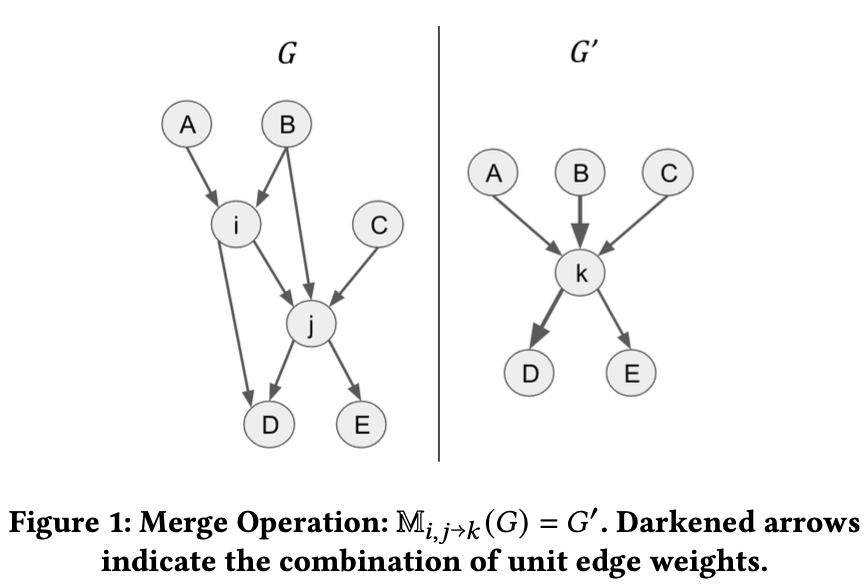
Sachin Konan*, Larry Rudolph, Two Sigma Research Archive , 2024 TLDR; Directed Graphs contain important dependencies and whose structure may be sensitive. Previous work has shown that node deanonymization isn't enough so we protect against subgraph isomorphism and Sybil attacks through the use of random perturbations (Merge-Split). For usability, the perturbed graph has to maintain similarity to the original, which is achieved by minimizing the change in the graph's eigenspace. Our experiments showed that Merge-Split locally disrupts random walks while maintaining overall structural properties, like the graph's steady-state distribution. |
|
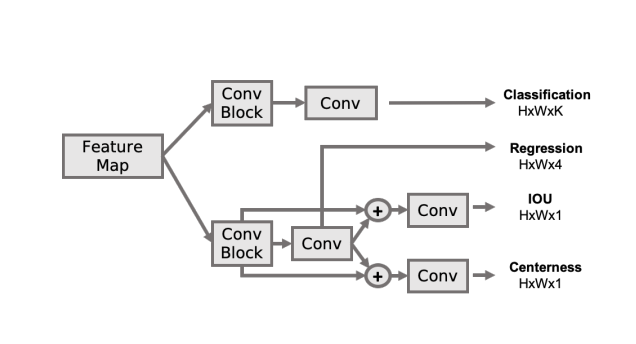
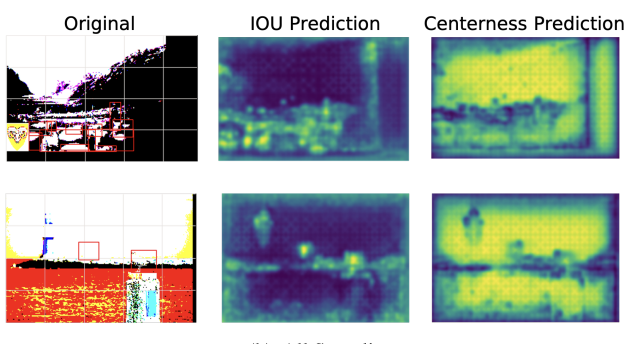
Sachin Konan*, Kevin J Liang, Li Yin arXiv pre-print, 2022 TLDR; Object Detection consists of the localization and classification of objects, and two-stage networks made this process conditional. However, in practice, one might want to localize any object, regardless of whether it can be classified (this is called Open World Detection (OWD)). Previously, two-stage networks have been studied, but we investigate a one-stage network called FCOS for its simplicity and decoupling of classification from localization. We investigate various architectural and sampling improvements that allow FCOS to retain is classification ability, while improving localization recall. |
|
Also, I wrote a blog post about the benefits of migrating datatable schemas from primitive data-types to entity-driven data-types, called Semantic Types. In FSTO-Gen, I used LLMs to automatically generate these types to automatically structure data. |
|
|